Introduction to Hadoop:




Hadoop is a open source software
framework for distributed processing of
large datasets across large clusters of computers.
0 or 1
|
bit
|
8 bits
|
1 byte
|
1024 bytes
|
1 KiloByte
|
1024 KB
|
1 MegaByte
|
1024 MB
|
1 GigaByte
|
1024 GB
|
1 TeraByte
|
1024 TB
|
1 PetaByte
|
1024 PB
|
1 ExaByte
|
1024 EB
|
1 ZettaByte
|
Hadoop History
Hadoop was derived from Google’s MapReduce and
Google File System (GFS) papers. Hadoop was created by Doug
Cutting and Michael J. Cafarella (Yahoo employees) and name by Doug’s son’s toy elephant.
Dec 2004
|
Google GFS paper
published
|
July 2005
|
Nutch uses
MapReduce
|
Feb 2006
|
Starts as a Lucene subproject
|
Apr 2007
|
Yahoo! on
1000-node cluster
|
Jan 2008
|
An Apache Top Level Project
|
Jul 2008
|
A 4000 node test
cluster
|
May 2009
|
Hadoop sorts Petabyte in 17 hours
|
1 Hard Disk =
100MB/sec (~1Gbps)
|
Server = 12
Hard Disks = 1.2GB/sec (~12Gbps)
|
Rack = 20 Servers = 24GB/sec (~240Gbps)
|
Avg. Cluster
= 6 Racks = 144GB/sec (~1.4Tbps)
|
Large Cluster
= 200 Racks = 4.8TB/sec (~48Tbps)
|
HADOOP
Hadoop is a open source software
framework for distributed processing of large datasets across large clusters of
computers.
Large datasets ? Terabytes or
petabytes of data
Large clusters ? hundreds or
thousands of nodes
(In other terms…)
It provides a distributed
files-system and a framework for the analysis and transformation of very large
data sets using the Map-Reduce paradigm.
Hadoop was inspired by Google's
MapReduce and Google File System (GFS).Hadoop is a top-level Apache project
being built and used by a global community of contributors, using the Java
programming language.Yahoo! has been the largest contributor to the project,
and uses Hadoop extensively across its businesses. Applications need a write-once-read-many
access model.
Hadoop framework consists on two
main layers:
Distributed file system (HDFS) -
Stands for Hadoop Distributed File System. It uses a framework involving many
machines which stores large amounts of data in files over a Hadoop cluster.
Execution engine (MapReduce) -
Map Reduce is a set of programs used to access and manipulate large data sets
over a Hadoop cluster.
ü
Hadoop
is a framework for running applications on large clusters built of commodity
hardware.
ü
The
Hadoop framework transparently provides applications both reliability and data
motion.
ü
Hadoop
implements a computational paradigm named
Map/Reduce, where the
application is divided into many small fragments of work, each of which
may be executed
or re-executed on any node in the cluster.
ü
In
addition, it provides a distributed file system (HDFS) that stores data on the
compute nodes, providing very high aggregate bandwidth across the cluster.
ü
Both Map/Reduce and the distributed file
system are designed so that node failures are automatically handled by the
framework.
Why Hadoop is able to compete?

-- Hadoop is not a database, it is an
architecture with a file system called HDFS. The data is stored in HDFS which
does not have any predefined containers.
-- Relational database stores data in
predefined containers.
Distributed Databases
|
Hadoop
|
|
Computing Model
|
- Notion
of transactions
- Transaction
is the unit of work
- ACID
properties, Concurrency control
|
- Notion
of jobs
- Job
is the unit of work
- No
concurrency control
|
Data Model
|
- Structured
data with known schema
- Read/Write
mode
|
- Any
data will fit in any format
- (un)(semi)structured
- ReadOnly
mode
|
Cost Model
|
- Expensive
servers
|
- Cheap
commodity machines
|
Fault Tolerance
|
- Failures
are rare
- Recovery
mechanisms
|
- Failures
are common over thousands of machines
- Simple
yet efficient fault tolerance
|
Key Characteristics
|
- Efficiency, optimizations, fine-tuning
|
- Scalability, flexibility, fault tolerance
|
Architecture
to start Hadoop. The package also
provides source code, documentation and a contribution
section that includes projects from
the Hadoop Community.
HDFS follows a master/slave architecture. An HDFS installation consists
of a single
Namenode, a master server that manages the File system
namespace and regulates
access to files by clients. In addition, there are a number of Datanodes,
one per node in
the cluster, which manage storage attached to the nodes that they run
on.
The Namenode makes file system namespace operations like opening,
closing, renaming
etc. of files and directories available via an RPC interface. It also
determines the mapping
of blocks to Datanodes.
The Datanodes are responsible for serving read and write requests
from filesystem
clients, they also perform block creation, deletion, and replication
upon instruction from
the Namenode.
Master node (Hadoop
currently configured with centurion064 as the master node)
Keeps track of namespace and
metadata about items
Keeps track of MapReduce jobs in
the system
Slave nodes (Centurion064
also acts as a slave node)
Manage blocks of data sent from
master node
In terms of GFS, these are the
chunk servers

Hadoop Master/Slave Architecture
Hadoop is designed as a master-slave shared-nothing architecture

Totally 5 daemons run in Hadoop
Master-slave architecture.
On Master Node : Name Node and
Job Tracker and Secondary name node
On Slave Node: Data Node and
Task Tracker
Name node:-
Name node is one of the daemon that
runs in Master node and holds the meta info where particular chunk of data (ie.
data node) resides. Based on meta info maps the incoming job to corresponding
data node. Name Node Handles data node failures through checksums. every data
has a record followed by a checksum. if checksum does not match with the
original then it reports an data corrupted error.
Name node is responsible for
managing the HDFS and Supplies address of the data on the different data nodes.
the name nodes require a specified amount of RAM to store file system image in
memory. the name node holds information about all the files in the system and
needs to be extra reliable. The name node will detect that a data node is not
responsive and will start replication of the data from remaining replicas. When
data node comes back online, the extra replicas will be deleted.
Note:- Replication Factor
controls how many times each individual blocks can be replicated.
Secondary name node:- Secondary
name node performs CPU intensive operation of combining edit logs and current
file system Snapshots. Its recommended to run Secondary name node in a separate
machine which have Master node capacity. If we are not running a secondary name
node ,cluster performance will degrade over time since edit log will grow
bigger and bigger.
Job Tracker:- The Job
Tracker is responsible for scheduling the tasks on slave nodes, collecting
results, retrying the failed jobs. There can only be one Job Tracker in the
cluster. This can be run on the same machine running the Name Node. It receives
heartbeat from task tracker based on which Job tracker decides whether the
assigned task is completed or not.
Note:- Default port number for job tracker is 50030.
Note:- Daemon is a process
or service that runs in background
Datanode:- Datanodes are the
slaves which are deployed on each machine and provide the
actual storage. The Datanodes are responsible for
serving read and write requests from file
System clients, they also perform
block creation, deletion, and replication upon instruction
From the Namenode .
Task tracker:-Task tracker
is also a daemon that runs on datanodes. Task Trackers manage the
execution of individual tasks on
slave node. When a client submits a job, the job tracker will
initialize the job and divide the
work and assign them to different task trackers to perform
MapReduce tasks.While performing
this action, the task tracker will be simultaneously
communicating with job tracker by
sending heartbeat. If the job tracker does not receive
heartbeat from task tracker within
specified time, then it will assume that task tracker has
crashed and assign that task to
another task tracker in the cluster.
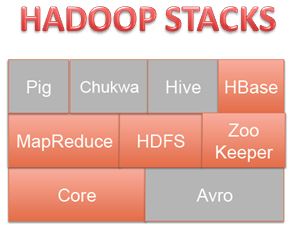
|
Pig- Platform for analyzing large data sets.PigLatin queries are
converted into map reduce jobs. Developed at Yahoo!
Hive-
Data ware housing tool on top of Hadoop. Provides SQL like interface/language
to analyze the data stored on HDFS. Developed at Facebook
HBase-
Persistent, distributed, sorted,multidimensional, sparse map. Based on Google
BigTable which provides interactive access to information
Sqoop–
import SQL-based data to Hadoop
|
|
References
|
|
[1] J. Dean
and S. Ghemawat, ``MapReduce: Simplied Data Processing on Large Clusters,’’
OSDI 2004. (Google)
[2] D.
Cutting and E. Baldeschwieler, ``Meet Hadoop,’’ OSCON, Portland, OR, USA, 25
July 2007 (Yahoo!)
[3] R. E.
Brayant, “Data Intensive Scalable computing: The case for DISC,” Tech Report:
CMU-CS-07-128, http://www.cs.cmu.edu/~bryant
|
No comments:
Post a Comment